
Hi everyone!
It’s been way too long, I know. In this oportunity, I wanted to talk about asynchronicity in Django, but first, lets set up the stage:
Imagine you are working in a library and you have to develop an app that allows users to register new books using a barcode scanner. The system has to read the ISBN code and use an external resource to fill in the information (title, pages, authors, etc.). You don’t need the complete book information to continue, so the external resource can’t hold the request.
How can you process the external request asynchronously? 🤔
For that, we need Celery.
What is Celery?
Celery is a “distributed task queue”. Fron their website:
> Celery is a simple, flexible, and reliable distributed system to process vast amounts of messages, while providing operations with the tools required to maintain such a system.
So Celery can get messages from external processes via a broker (like Redis), and process them.
The best thing is: Django can connect to Celery very easily, and Celery can access Django models without any problem. Sweet!
Lets code!
Let’s assume our project structure is the following:
- app/
- manage.py
- app/
- __init__.py
- settings.py
- urls.py
Celery
First, we need to set up Celery in Django. Thankfully, Celery has an excellent documentation, but the entire process can be summarized to this:
In app/app/celery.py:
import os
from celery import Celery
# set the default Django settings module for the 'celery' program.
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "app.settings")
app = Celery("app")
# Using a string here means the worker doesn't have to serialize
# the configuration object to child processes.
# - namespace='CELERY' means all celery-related configuration keys
# should have a `CELERY_` prefix.
app.config_from_object("django.conf:settings", namespace="CELERY")
# Load task modules from all registered Django app configs.
app.autodiscover_tasks()
@app.task(bind=True)
def debug_task(self):
"""A debug celery task"""
print(f"Request: {self.request!r}")
What’s going on here?
- First, we set the
DJANGO_SETTINGS_MODULEenvironment variable - Then, we instantiate our Celery app using the
appvariable. - Then, we tell Celery to look for celery configurations in the Django settings
with the
CELERYprefix. We will see this later in the post. - Finally, we start Celery’s
autodiscover_tasks. Celery is now going to look fortasks.pyfiles in the Django apps.
In /app/app/__init__.py:
# This will make sure the app is always imported when
# Django starts so that shared_task will use this app.
from .celery import app as celery_app
__all__ = ("celery_app",)
Finally in /app/app/settings.py:
...
# Celery
CELERY_BROKER_URL = env.str("CELERY_BROKER_URL")
CELERY_TIMEZONE = env.str("CELERY_TIMEZONE", "America/Montevideo")
CELERY_RESULT_BACKEND = "django-db"
CELERY_CACHE_BACKEND = "django-cache"
...
Here, we can see that the CELERY prefix is used for all Celery configurations,
because on celery.py we told Celery the prefix was CELERY
With this, Celery is fully configured. 🎉
Django
First, let’s create a core app. This is going to be used for everything common
in the app
$ python manage.py startapp core
On core/models.py, lets set the following models:
"""
Models
"""
import uuid
from django.db import models
class TimeStampMixin(models.Model):
"""
A base model that all the other models inherit from.
This is to add created_at and updated_at to every model.
"""
id = models.UUIDField(primary_key=True, default=uuid.uuid4)
created_at = models.DateTimeField(auto_now_add=True)
updated_at = models.DateTimeField(auto_now=True)
class Meta:
"""Setting up the abstract model class"""
abstract = True
class BaseAttributesModel(TimeStampMixin):
"""
A base model that sets up all the attibutes models
"""
name = models.CharField(max_length=255)
outside_url = models.URLField()
def __str__(self):
return self.name
class Meta:
abstract = True
Then, let’s create a new app for our books:
python manage.py startapp books
And on books/models.py, let’s create the following models:
"""
Books models
"""
from django.db import models
from core.models import TimeStampMixin, BaseAttributesModel
class Author(BaseAttributesModel):
"""Defines the Author model"""
class People(BaseAttributesModel):
"""Defines the People model"""
class Subject(BaseAttributesModel):
"""Defines the Subject model"""
class Book(TimeStampMixin):
"""Defines the Book model"""
isbn = models.CharField(max_length=13, unique=True)
title = models.CharField(max_length=255, blank=True, null=True)
pages = models.IntegerField(default=0)
publish_date = models.CharField(max_length=255, blank=True, null=True)
outside_id = models.CharField(max_length=255, blank=True, null=True)
outside_url = models.URLField(blank=True, null=True)
author = models.ManyToManyField(Author, related_name="books")
person = models.ManyToManyField(People, related_name="books")
subject = models.ManyToManyField(Subject, related_name="books")
def __str__(self):
return f"{self.title} - {self.isbn}"
Author, People, and Subject are all BaseAttributesModel, so their fields
come from the class we defined on core/models.py.
For Book we add all the fields we need, plus a many_to_many with Author,
People and Subjects. Because:
- Books can have many authors, and many authors can have many books
Example: 27 Books by Multiple Authors That Prove the More, the Merrier
- Books can have many persons, and many persons can have many books
Example: Ron Weasley is in several Harry Potter books
- Books can have many subjects, and many subjects can have many books
Example: A book can be a comedy, fiction, and mystery at the same time
Let’s create books/serializers.py:
"""
Serializers for the Books
"""
from django.db.utils import IntegrityError
from rest_framework import serializers
from books.models import Book, Author, People, Subject
from books.tasks import get_books_information
class AuthorInBookSerializer(serializers.ModelSerializer):
"""Serializer for the Author objects inside Book"""
class Meta:
model = Author
fields = ("id", "name")
class PeopleInBookSerializer(serializers.ModelSerializer):
"""Serializer for the People objects inside Book"""
class Meta:
model = People
fields = ("id", "name")
class SubjectInBookSerializer(serializers.ModelSerializer):
"""Serializer for the Subject objects inside Book"""
class Meta:
model = Subject
fields = ("id", "name")
class BookSerializer(serializers.ModelSerializer):
"""Serializer for the Book objects"""
author = AuthorInBookSerializer(many=True, read_only=True)
person = PeopleInBookSerializer(many=True, read_only=True)
subject = SubjectInBookSerializer(many=True, read_only=True)
class Meta:
model = Book
fields = "__all__"
class BulkBookSerializer(serializers.Serializer):
"""Serializer for bulk book creating"""
isbn = serializers.ListField()
def create(self, validated_data):
return_dict = {"isbn": []}
for isbn in validated_data["isbn"]:
try:
Book.objects.create(isbn=isbn)
return_dict["isbn"].append(isbn)
except IntegrityError as error:
pass
return return_dict
def update(self, instance, validated_data):
"""The update method needs to be overwritten on
serializers.Serializer. Since we don't need it, let's just
pass it"""
pass
class BaseAttributesSerializer(serializers.ModelSerializer):
"""A base serializer for the attributes objects"""
books = BookSerializer(many=True, read_only=True)
class AuthorSerializer(BaseAttributesSerializer):
"""Serializer for the Author objects"""
class Meta:
model = Author
fields = ("id", "name", "outside_url", "books")
class PeopleSerializer(BaseAttributesSerializer):
"""Serializer for the Author objects"""
class Meta:
model = People
fields = ("id", "name", "outside_url", "books")
class SubjectSerializer(BaseAttributesSerializer):
"""Serializer for the Author objects"""
class Meta:
model = Subject
fields = ("id", "name", "outside_url", "books")
The most important serializer here is BulkBookSerializer. It’s going to get an
ISBN list and then bulk create them in the DB.
On books/views.py, we can set the following views:
"""
Views for the Books
"""
from rest_framework import viewsets, mixins, generics
from rest_framework.permissions import AllowAny
from books.models import Book, Author, People, Subject
from books.serializers import (
BookSerializer,
BulkBookSerializer,
AuthorSerializer,
PeopleSerializer,
SubjectSerializer,
)
class BookViewSet(
viewsets.GenericViewSet,
mixins.ListModelMixin,
mixins.RetrieveModelMixin,
):
"""
A view to list Books and retrieve books by ID
"""
permission_classes = (AllowAny,)
queryset = Book.objects.all()
serializer_class = BookSerializer
class AuthorViewSet(
viewsets.GenericViewSet,
mixins.ListModelMixin,
mixins.RetrieveModelMixin,
):
"""
A view to list Authors and retrieve authors by ID
"""
permission_classes = (AllowAny,)
queryset = Author.objects.all()
serializer_class = AuthorSerializer
class PeopleViewSet(
viewsets.GenericViewSet,
mixins.ListModelMixin,
mixins.RetrieveModelMixin,
):
"""
A view to list People and retrieve people by ID
"""
permission_classes = (AllowAny,)
queryset = People.objects.all()
serializer_class = PeopleSerializer
class SubjectViewSet(
viewsets.GenericViewSet,
mixins.ListModelMixin,
mixins.RetrieveModelMixin,
):
"""
A view to list Subject and retrieve subject by ID
"""
permission_classes = (AllowAny,)
queryset = Subject.objects.all()
serializer_class = SubjectSerializer
class BulkCreateBook(generics.CreateAPIView):
"""A view to bulk create books"""
permission_classes = (AllowAny,)
queryset = Book.objects.all()
serializer_class = BulkBookSerializer
Easy enough, endpoints for getting books, authors, people and subjects and an endpoint to post ISBN codes in a list.
We can check swagger to see all the endpoints created:
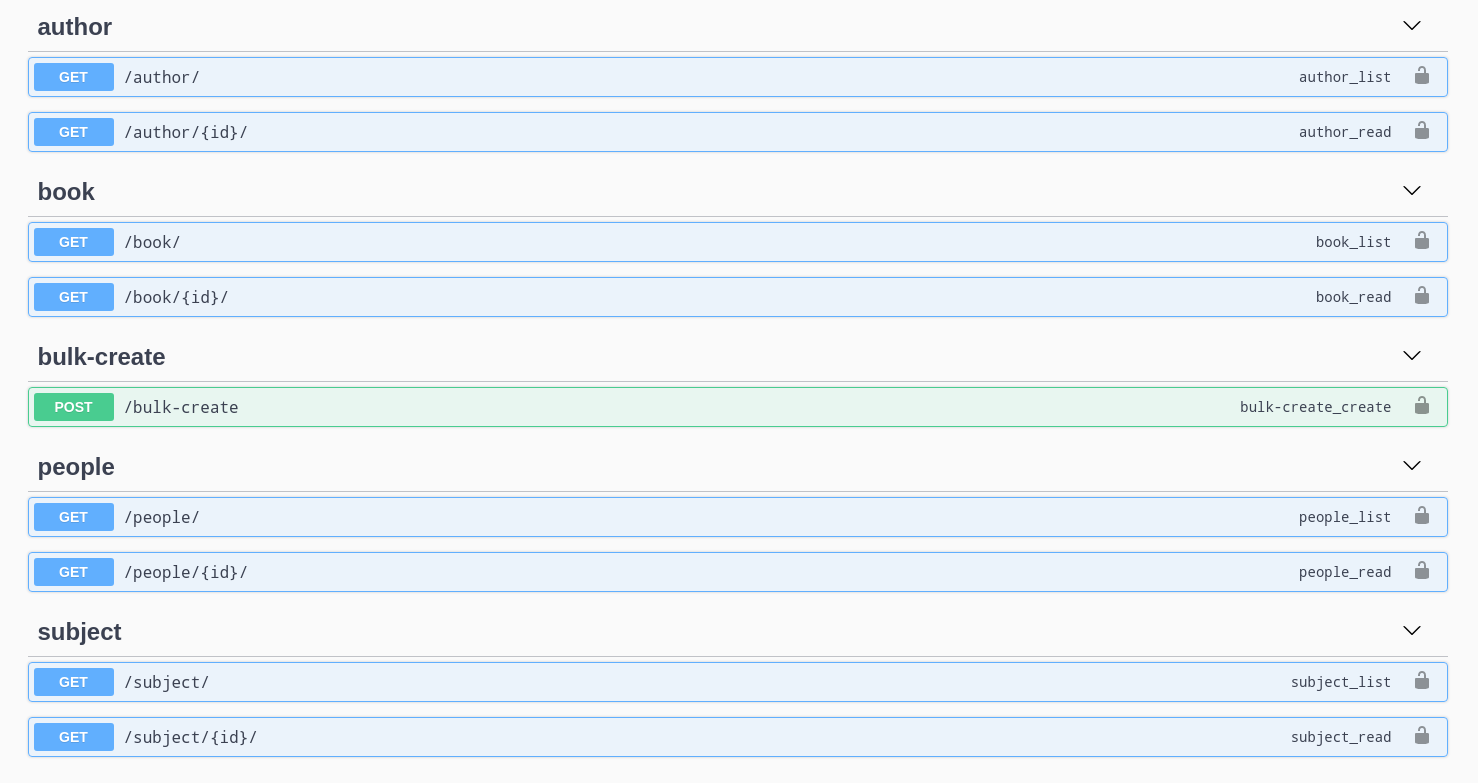
Now, how are we going to get all the data? 🤔
Creating a Celery task
Now that we have our project structure done, we need to create the asynchronous task Celery is going to run to populate our fields.
To get the information, we are going to use the OpenLibrary API.
First, we need to create books/tasks.py:
"""
Celery tasks
"""
import requests
from celery import shared_task
from books.models import Book, Author, People, Subject
def get_book_info(isbn):
"""Gets a book information by using its ISBN.
More info here https://openlibrary.org/dev/docs/api/books"""
return requests.get(
f"https://openlibrary.org/api/books?jscmd=data&format=json&bibkeys=ISBN:{isbn}"
).json()
def generate_many_to_many(model, iterable):
"""Generates the many to many relationships to books"""
return_items = []
for item in iterable:
relation = model.objects.get_or_create(
name=item["name"], outside_url=item["url"]
)
return_items.append(relation)
return return_items
@shared_task
def get_books_information(isbn):
"""Gets a book information"""
# First, we get the book information by its isbn
book_info = get_book_info(isbn)
if len(book_info) > 0:
# Then, we need to access the json itself. Since the first key is dynamic,
# we get it by accessing the json keys
key = list(book_info.keys())[0]
book_info = book_info[key]
# Since the book was created on the Serializer, we get the book to edit
book = Book.objects.get(isbn=isbn)
# Set the fields we want from the API into the Book
book.title = book_info["title"]
book.publish_date = book_info["publish_date"]
book.outside_id = book_info["key"]
book.outside_url = book_info["url"]
# For the optional fields, we try to get them first
try:
book.pages = book_info["number_of_pages"]
except:
book.pages = 0
try:
authors = book_info["authors"]
except:
authors = []
try:
people = book_info["subject_people"]
except:
people = []
try:
subjects = book_info["subjects"]
except:
subjects = []
# And generate the appropiate many_to_many relationships
authors_info = generate_many_to_many(Author, authors)
people_info = generate_many_to_many(People, people)
subjects_info = generate_many_to_many(Subject, subjects)
# Once the relationships are generated, we save them in the book instance
for author in authors_info:
book.author.add(author[0])
for person in people_info:
book.person.add(person[0])
for subject in subjects_info:
book.subject.add(subject[0])
# Finally, we save the Book
book.save()
else:
raise ValueError("Book not found")
So when are we going to run this task? We need to run it in the serializer.
On books/serializers.py:
from books.tasks import get_books_information
...
class BulkBookSerializer(serializers.Serializer):
"""Serializer for bulk book creating"""
isbn = serializers.ListField()
def create(self, validated_data):
return_dict = {"isbn": []}
for isbn in validated_data["isbn"]:
try:
Book.objects.create(isbn=isbn)
# We need to add this line
get_books_information.delay(isbn)
#################################
return_dict["isbn"].append(isbn)
except IntegrityError as error:
pass
return return_dict
def update(self, instance, validated_data):
pass
To trigger the Celery tasks, we need to call our function with the delay
function, which has been added by the shared_task decorator. This tells Celery
to start running the task in the background since we don’t need the result
right now.
Docker configuration
There are a lot of moving parts we need for this to work, so I created a
docker-compose configuration to help with the stack. I’m using the package
django-environ to handle all environment variables.
On docker-compose.yml:
version: "3.7"
x-common-variables: &common-variables
DJANGO_SETTINGS_MODULE: "app.settings"
CELERY_BROKER_URL: "redis://redis:6379"
DEFAULT_DATABASE: "psql://postgres:postgres@db:5432/app"
DEBUG: "True"
ALLOWED_HOSTS: "*,test"
SECRET_KEY: "this-is-a-secret-key-shhhhh"
services:
app:
build:
context: .
volumes:
- ./app:/app
environment:
<<: *common-variables
ports:
- 8000:8000
command: >
sh -c "python manage.py migrate &&
python manage.py runserver 0.0.0.0:8000"
depends_on:
- db
- redis
celery-worker:
build:
context: .
volumes:
- ./app:/app
environment:
<<: *common-variables
command: celery --app app worker -l info
depends_on:
- db
- redis
db:
image: postgres:12.4-alpine
environment:
- POSTGRES_DB=app
- POSRGRES_USER=postgres
- POSTGRES_PASSWORD=postgres
redis:
image: redis:6.0.8-alpine
This is going to set our app, DB, Redis, and most importantly our celery-worker instance. To run Celery, we need to execute:
$ celery --app app worker -l info
So we are going to run that command on a separate docker instance
Testing it out
If we run
$ docker-compose up
on our project root folder, the project should come up as usual. You should be able to open http://localhost:8000/admin and enter the admin panel.
To test the app, you can use a curl command from the terminal:
curl -X POST "http://localhost:8000/books/bulk-create" -H "accept: application/json" \
-H "Content-Type: application/json" -d "{ \"isbn\": [ \"9780345418913\", \
\"9780451524935\", \"9780451526342\", \"9781101990322\", \"9780143133438\" ]}"

This call lasted 147ms, according to my terminal.
This should return instantly, creating 15 new books and 15 new Celery tasks, one
for each book. You can also see tasks results in the Django admin using the
django-celery-results package, check its documentation.
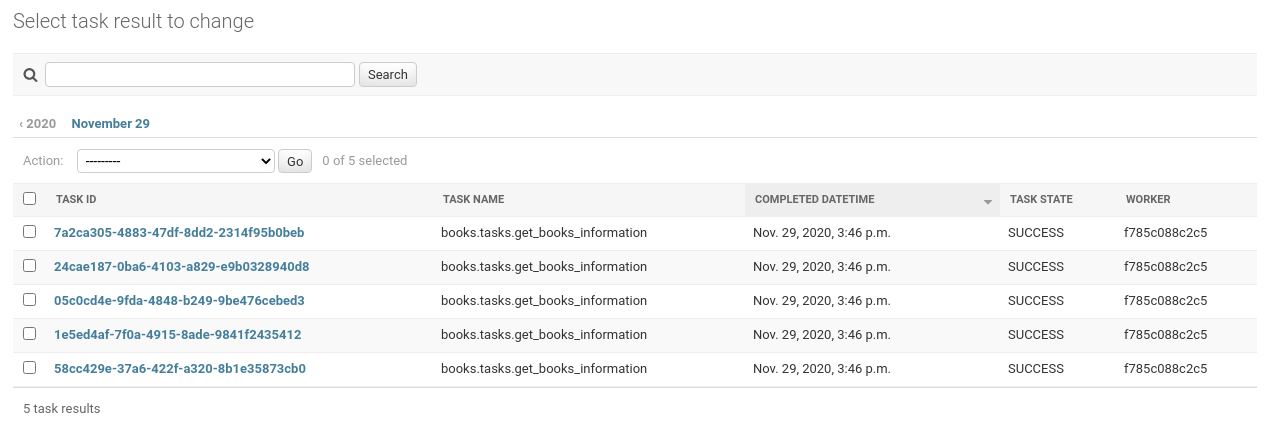
Celery tasks list, using django-celery-results
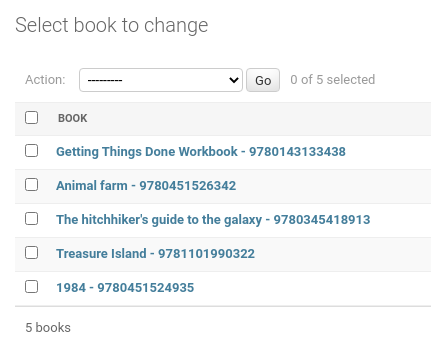
Created and processed books list
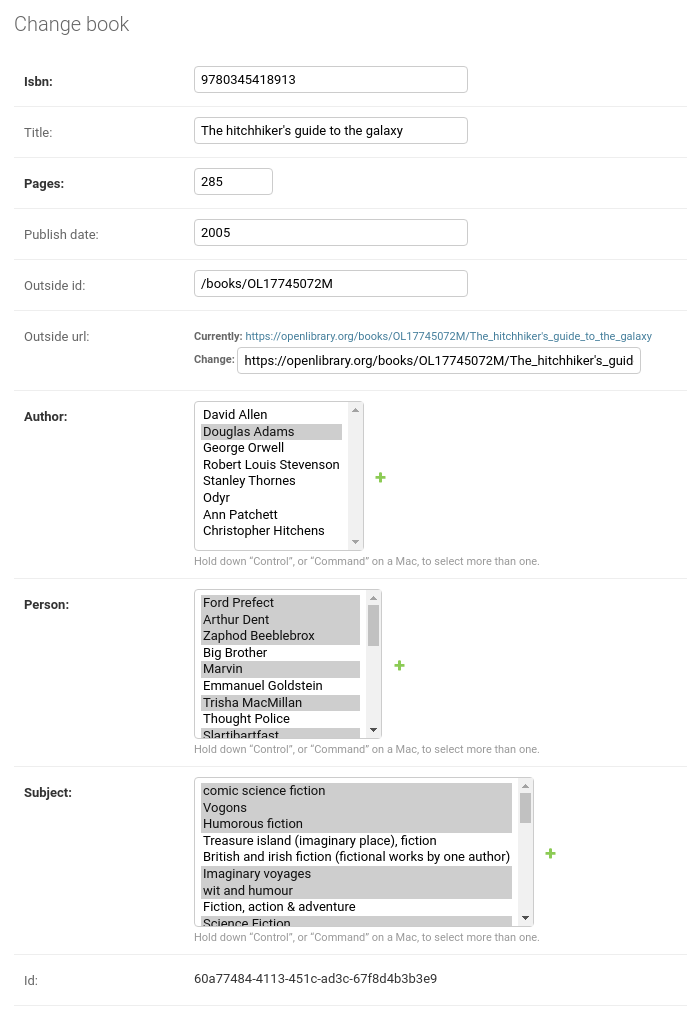
Single book information
People in books
Authors
Themes
And also, you can interact with the endpoints to search by author, theme, people, and book. This should change depending on how you created your URLs.
That’s it!
This surely was a LONG one, but it has been a very good one in my opinion. I’ve used Celery in the past for multiple things, from sending emails in the background to triggering scraping jobs and running scheduled tasks (like a unix cronjob)
You can check the complete project in my GitLab here: https://gitlab.com/rogs/books-app
If you have any doubts, let me know! I always answer emails and/or messages.